
Computational Engineering 101 – Part 6: Developing Algorithms on Paper
A Habit for Novices and Experts
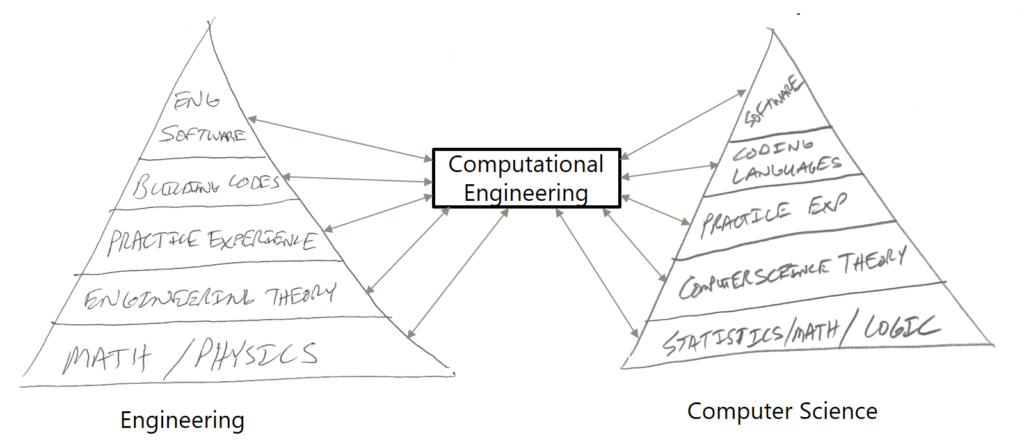
Recall from Part 3 that the key skills of a Computational Engineer lie somewhere between the two pyramids of Engineering first-principles and Computer Science first-principles. In Part 4 and Part 5, you should have gained an appreciation for Object Oriented Programming and a basic understanding of algorithms. You now have started to build up a decent base of knowledge on your Computer Science pyramid. Now we must learn how to combine this new knowledge with our engineering knowledge to create value with the machine. A key mistake many engineers make on at the beginning of the Computational Engineering journey is to jump straight onto their Integrated Development Environment (IDE) of choice and attempt to start coding right away. Don’t do this. This is a great way to get lost, frustrated, and lose control. Even experienced coders cannot pull this off successfully. Instead, it is key that you develop the skill of developing algorithms on paper before you turn to the machine to code. As we will show, not only does this help you develop better algorithms now and in the future, but also, it will serve to expedite your learning process.
Developing Algorithms on Paper – The I/O Board
The Bread Making Algorithm
Take out a piece of paper. Lay it out in front of you. On the top left side, write “I”. On the top right side, write “O”. You are officially on your way to having the computer be your design sidekick. Remember, the computer is really good at taking a recipe and making it. On this I/O board, we will effectively define as specifically as possible (computers are dumb, the need you to be ultra-specific), what are the ingredients and what are the steps of the recipe.
I/O stands for “input and output” and the space that lies between them is the interconnectivty of those two items, which is your algorithm. Both your input and your output are objects. The processes in between those two may create new objects, or modify or get data from the input object to create the output object.
Iteration 1
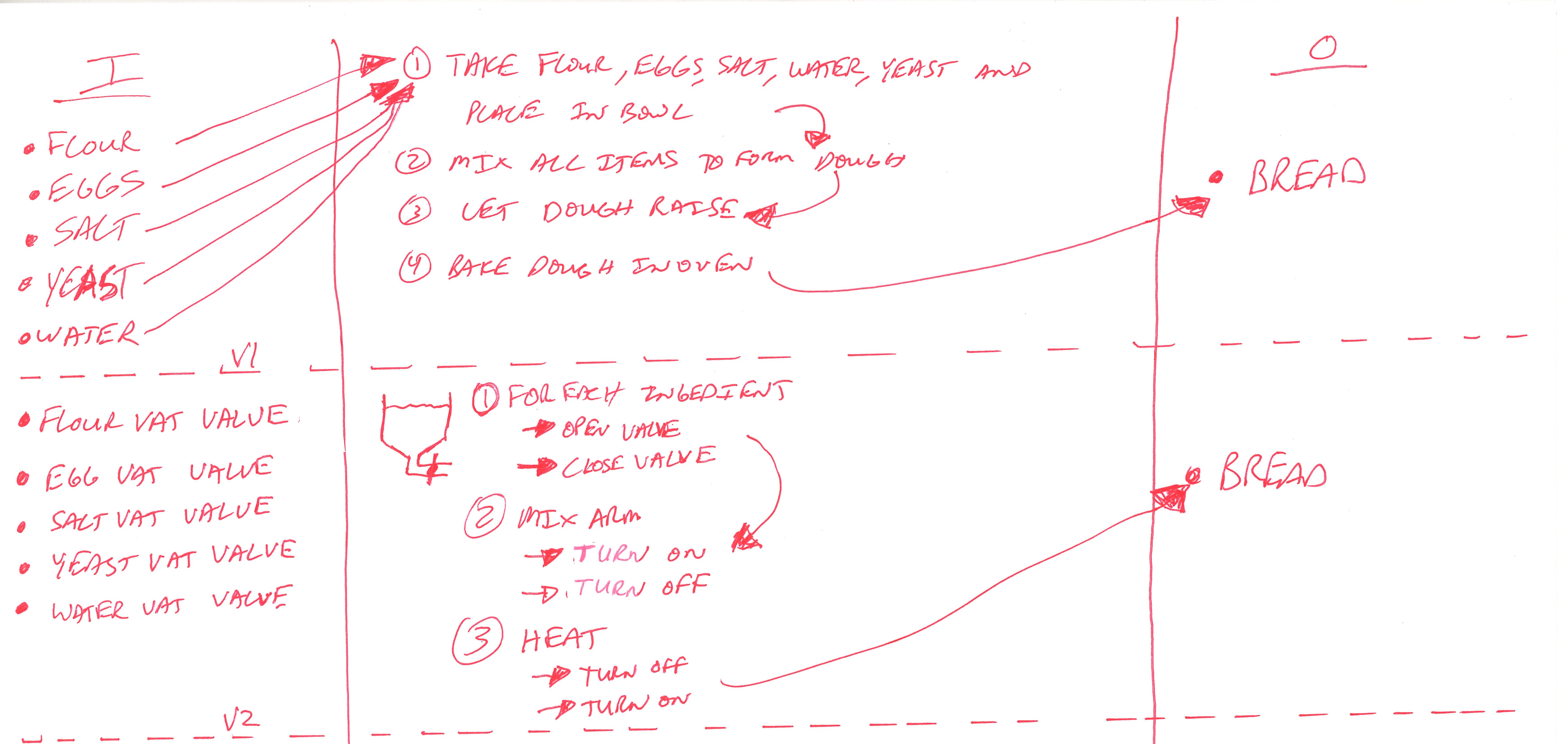
Let’s do an example to show how we would hand this. Sticking with the recipe example, let’s make an algorithm for a robot that will create bread for us. Let’s start with what we have, and what we want to get to:
![]()

Simple enough right? All that beautiful white space on that diagram is where we get to have some fun developing our algorithm on paper. Most importantly, we will gain a full understanding our problem by breaking it down into manageable pieces for the machine. Let’s first add the steps we’d need to do to the inputs to get the outputs:


This is pretty much a recipe for bread, it just looks different because instead of just writing the steps using bullet points, we’re writing it laterally and connecting with arrows. One would say we’ve nailed the first-principles of bread making here as a first pass. But our goal is to get the machine to execute this, therefore, this cannot be the final algorithm – it has nothing to do with a computer. It can only be read by a human who speaks English and is vaguely familiar with cooking terminology. For us to get closer to figuring out how do get the computer (the brain of our robot) to make us bread, we have to modify this algorithm to be a bit more empathetic to the fact it’s being carried out by a machine. In other words, we have to translate it from English to computer lingo. We will do this on paper – resist the urge here to jump into the code!
Iteration 2
For us to start developing our algorithm further, let us first look at the inputs in a more specific manner. Recall our key question from Part 4 – What does the computer see? How can it possibly know what are eggs, and flour? This takes an appreciation for what a computer can know and how (specifically) a computer would store information about such objects. Let’s assume the physical inputs to the bread machine are big cylinders with valves at the bottom and that each item is pre-processed elsewhere (i.e. eggs are cracked). Now what would the algorithm look like? Add that to your I/O board and you may now have a second version of the algorithm like this:

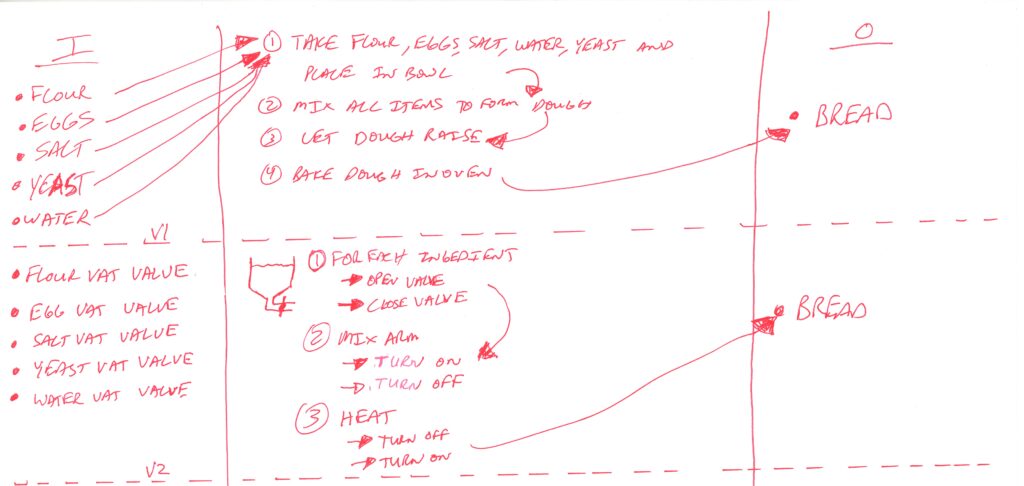
So the first iteration (v1) of this problem on paper was only empathetic to humans. The second iteration (v2) has taken a baby step towards being empathetic with the machine by simply changing the structure of the inputs. Instead of food objects, we have vat objects. This difference has had a knock on implication for how we structure our algorithms to get to the same output.
Iteration 3
What if one loaf of bread requires 3 eggs? In v1 of the algorithm, we’d just write down “3 eggs”. In v2, it’s not as straightforward as in v1 – now we just have a huge vat of battered eggs! How can we assure our bread will only contain 3 eggs? To develop our algorithm further, we’ll have to define our problem a bit more clearly. Say we add a weight meter to our machine so it can track how much volume of egg and other ingredients it has input to the mix. The affect of this new information could lead to v3 of the algorithm such as this:

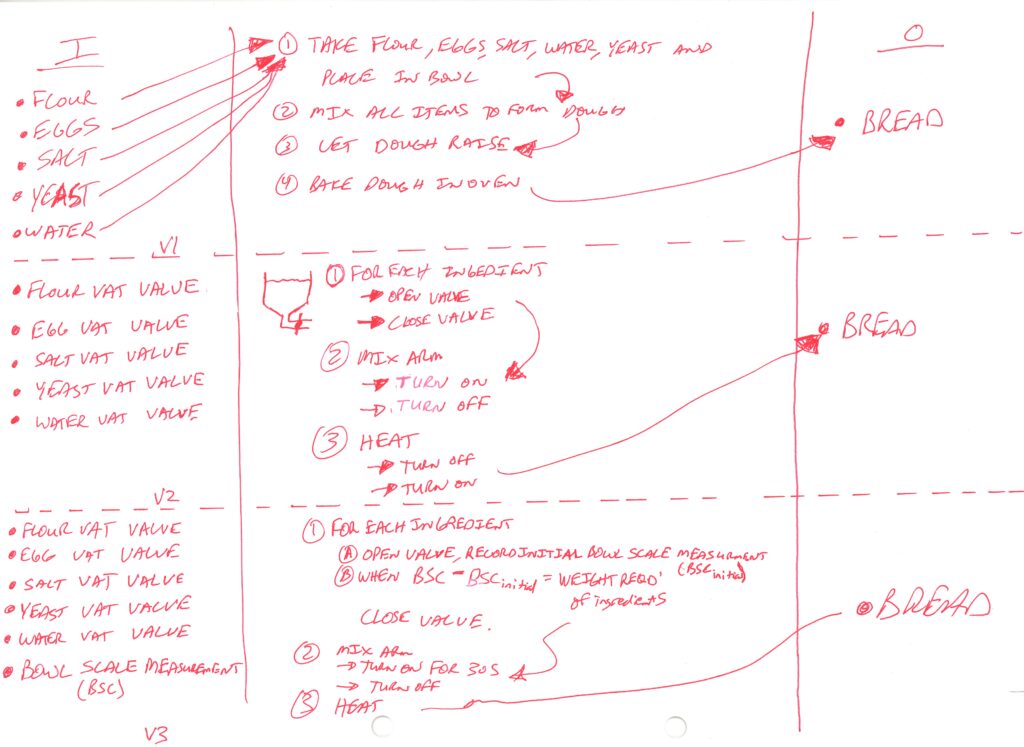
This example could go on for many more iterations, but at that point, we’d actually be creating the machine! The key here is to understand that the idea of the I/O board is to understand how to convert the steps of your solution from English to something more specific and empathetic to the machines world view.
For instance, now that you have done these three iterations, imagine if we had a machine that instead of taking in a vat of scrambled raw eggs, instead, it used an apparatus like this:

This would impact our algorithm in a few different ways. For instance, it would preclude the need for the flowmeter we added between v2/v3.
Iteration N
The key to take away from this process is that we started from human first principles and created our recipe. Then, we started to pivot that definition and start putting it in terms that the computer can understand. As we go from version to version, the steps we lay out become more and more empathetic to the specifics to the mechanics we’ll use on the computer to get the computer to produce work (bread) for us. Developing algorithms on paper in this way is a key skill of any Computational Engineer. The algorithm will be refined further and further in subsequent iterations until we are literally speaking the computer’s language (code) in vN of the code instead of the human language (English) that we had in v1. In C#, our final iteration may look like this for step 1:
List<Vat> Vats = new List<Vat>();
Vats = Machine.DetectNumberofVats();
foreach (Vat ingredient in Vats)
{
double amountRequired = ingredient.requiredIngredientWeight
double weight_initial = Machine.ScaleReading();
while (Machine.ScaleReading()-weight_initial<amountRequired)
{
ingredient.ValveOpen();
}
ingredient.ValveClose();
}
If you notice, the human definition seems much less involved than that computer definition. That’s because a computer is dumb. The computer has no idea what it is we want. It doesn’t know what bread is, nor eggs, nor salt and it will never know what those are. It doesn’t know anything. It only knows how to handle 0’s and 1’s on scales that humans can’t even fathom. For you to communicate with the machine and get it to do work for you, you will need to be empathetic with this fact. Furthermore, you will need to get good at digging to the heart of what you problem is down to ‘bedrock’. To hit ‘bedrock in this sense means deconstructing your problems from english recipes to recipes that are well-defined, quantitative, and in a position to be coded.
The Art of Computational Engineering
By using the I/O board, you will become a better Computational Engineer. It will keep you focused on first-principles whilst also showing you how pedantic it can be to explain a task to a machine to do. It will also help you not to ‘get lost in the weeds’ when you are sitting down to code the instructions. If you can come up with your algorithm on paper like this, then your coding it becomes much easier as you are able to break off little chunks one at a time and code each of them one by one. This is especially important when you are just starting off. All of your creative thinking should be complete before you start coding, as you’ll have your hands full dealing with coding-specific issues, such as debugging when it’s finally time to hit the IDE and code. Put another way:
“Don’t you guys feel like when you’re using Grasshopper [coding] you’re seeing the world through a straw?
-Carl Bass, Fabricate 2017 Conference in Stuttgart
This technique will make your learning of the syntax’s of your coding language of choice easier as well as the list of instructions for the computer to execute will effectively give you a list of micro-lessons to carry out.
